 |
IPSDK 4.1
IPSDK : Image Processing Software Development Kit
|
|
IPSDK 4.1
IPSDK : Image Processing Software Development Kit
|
| ClustersCenters = | kMeansPPClusterInit (inImg,inNbClusters) |
| ClustersCenters = | kMeansPPClusterInit (inImg,inOptSingleGreyMaskImg,inNbClusters) |
| ClustersCenters = | nonRandomKMeansPPClusterInit (inImg,inNbClusters) |
| ClustersCenters = | nonRandomKMeansPPClusterInit (inImg,inOptSingleGreyMaskImg,inNbClusters) |
Initializes the clusters for K-Mean classification.
Classical random K-means algorithm initialization can lead to a sub-optimal classification and can vary between two calculations. Defining a relevant cluster initialization is an important problem in order to produce a robust and repeatable classification.
This algorithm can compute two versions of the K-Means++ initialization algorithm :
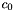 , just like for the classical K-Means.
, just like for the classical K-Means.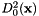 is then compute between this center and each pixels of the image :
is then compute between this center and each pixels of the image :
![\[ D^2_0(\textbf{x}) = \Vert InImg(\textbf{x}) - c_0 \Vert^2 \]](form_276.png)
![\[ \frac{D^2_0(\textbf{x})}{\sum_{\textbf{x}}{D^2_0(\textbf{x})}} \]](form_277.png)
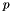 is also generated in order to have
is also generated in order to have ![$p \in \left[ 0, \sum_{\textbf{x}}{D^2_0(\textbf{x})} \right]$](form_279.png) . The new center is the first pixel where the cumulated distance is greater than .
. The new center is the first pixel where the cumulated distance is greater than .
![\[ D^2_i(\textbf{x}) = \min_{k \in \left[ 0, N \right]} (D^2_k(\textbf{x})), i > 0 \]](form_280.png)
is calculated as described above.Here is an example of a non-random cluster center classification on a UInt8 gray-level image with 5 clusters:
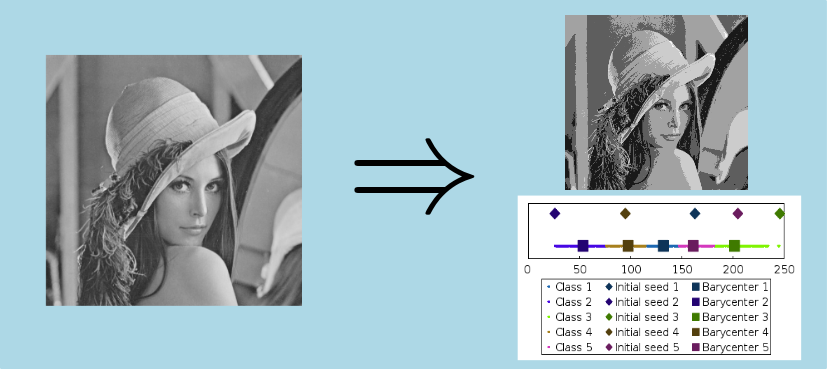
We can read on the abscissa axis the grey level intensity. The small points represent the pixels in the image, colored according to the cluster initialization. The squares illustrates the final cluster centers whereas the diamonds correspond to the first center as described in the step 1 of one of the algorithm versions.
If a mask image is provided, only pixels where the mask equals True can be used as a center. In the random case, the first center is randomly defined and until it corresponds to a value of False in the mask image. In the non-random case, the first center is the first pixel where the mask equals True: the first line is scanned, if all the pixels in the first line have False in the mask image, the second line is scanned, etc. To define the other centers, only pixels where the mask image equals True are used for the distance map calculation.
[1] "K-means++: The Advantages of Careful Seeding", Arthur, D. and Vassilvitskii, S, Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 2007, 1027-1035
